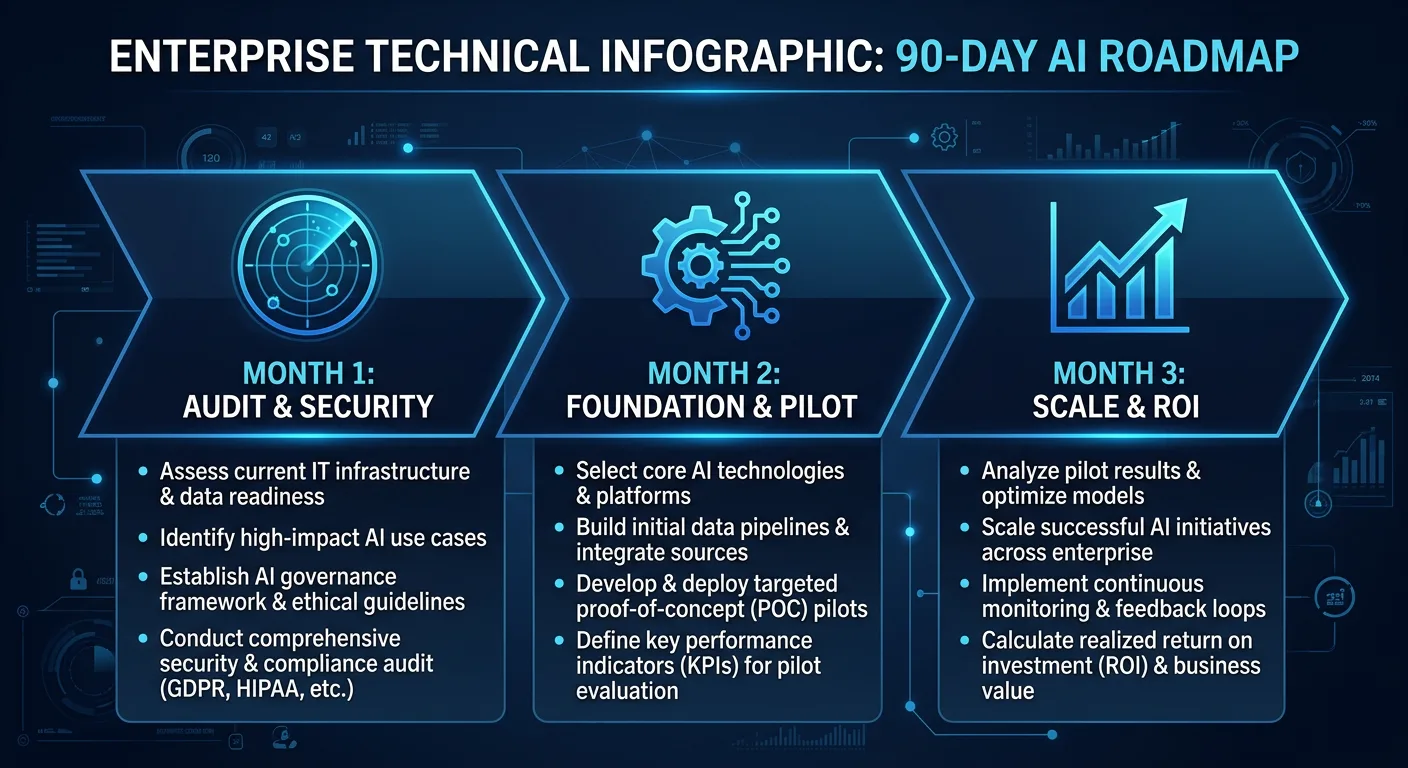
The 90-Day Fractional CAIO Operational Roadmap
The Fractional Chief AI Officer (CAIO) role is an operational leadership model that provides mid-market companies with strategic AI oversight and production-grade implementation at a fraction of the cost of a full-time executive hire.
This roadmap outlines the exact phases required to move an organization from "AI-curious" to "AI-automated" in 90 days. Not the vague strategy deck version. The real one, with timelines, deliverables, and the uncomfortable conversations you'll need to have along the way.
I've run this playbook across multiple mid-market companies (200 to 2,000 employees). The structure holds. The details change based on industry, existing tech stack (for a deep dive, see how a fractional CAIO builds an enterprise AI stack), and how honest the leadership team is willing to be about their current state. But the 90-day arc is consistent: audit, build, scale.
At a Glance: 90-Day Transformation Metrics
| Phase | Focus | Primary Goal | Target Efficiency Gain |
|---|---|---|---|
| Month 1 | Audit & Security | Stop Data Leaks | 15% Risk Mitigation |
| Month 2 | Foundation & Pilot | Deploy First AI Fleet | 30% Workflow Optimization |
| Month 3 | Execution & Scale | Handover & 3-Year Plan | $100K+ Annualized Savings |
I. Month 1: The Audit and Leak Assessment (Days 1 to 30)

Objective: Map the "Shadow AI" landscape, quantify the risk in real dollars, and identify the highest-ROI entry points for AI deployment.
Most companies think they're starting from zero with AI. They're not. They're starting from chaos. Employees are already using AI tools, just without oversight, security, or coordination. Month 1 is about getting honest about that reality.
1.1 The Shadow AI Audit
Before building anything, we need to stop the bleeding. In 2026, the primary threat to mid-market data integrity isn't external hackers. It's your own employees pasting sensitive company data into personal ChatGPT and Claude accounts.
The numbers are worse than most executives expect. According to JumpCloud's 2026 data, 80% of office workers use public AI tools without IT approval. Reco.ai's Shadow AI Report found enterprises average 269 shadow AI tools per 1,000 employees. And Harmonic Security's analysis of 22.4 million enterprise prompts across 665 AI tools uncovered 579,113 instances of sensitive data exposure. That's not a theoretical risk. That's data walking out the door every single day.
The audit itself follows a three-track approach:
- Technical discovery: Network traffic analysis, SaaS discovery tools (like Reco, Grip, or Nudge Security), and browser extension audits to identify which AI tools are actually being used and how often.
- Behavioral audit: Anonymous employee surveys and department interviews to understand why people are using unauthorized tools. The "why" matters as much as the "what." Usually the answer is that sanctioned tools don't exist, are too slow to get approved, or don't solve the actual problem.
- Data exposure assessment: Sampling AI tool usage logs (where available) and classifying what types of data are being shared. Harmonic Security's research shows legal content makes up 35% of sensitive data exposed to shadow AI, with financial data at 16.6%. For regulated industries, this is the number that gets the board's attention.
1.2 Quantifying the Leak in Dollars
The audit isn't just a risk exercise. It's a financial exercise. When 20% of organizations experienced security incidents linked to shadow AI in 2025, and breaches added an average of $670,000 to incident costs, you need a dollar figure attached to the exposure.
We build a risk exposure model for each client based on three factors: volume of sensitive data flowing to unsanctioned tools, regulatory exposure (HIPAA, SOC 2, GDPR, industry-specific requirements), and the cost of a breach in their specific context. That model becomes the business case for everything that follows. It's also the number that makes the CEO stop treating AI governance as an IT problem and start treating it as a board-level priority.
Protocol Zero gets established immediately: an Interim AI Usage Policy. This isn't a ban. Bans don't work; 60% of employees say they'd accept security risks to keep working faster with AI tools. Instead, it's a redirection. We channel existing AI usage into secure, company-sanctioned environments while the longer-term infrastructure gets built.
1.3 Stakeholder Interviews and Workflow Intelligence
We don't automate for the sake of automation. Every potential AI deployment gets scored on two axes: technical feasibility and business impact. But the scoring only works if you have honest data about how the business actually operates, not how the org chart says it operates.
Stakeholder interviews happen across every department. The questions are specific:
- What tasks consume more than 40% of your team's time but require less than 20% of their expertise?
- Where do handoffs between departments create delays or errors?
- What information do people search for repeatedly that should be instantly accessible?
- Which processes have been "described but not delivered" in past technology initiatives?
We use a framework adapted from McKinsey's approach to task categorization: have employees sort their own daily tasks into three buckets. Automate (AI handles it end-to-end), augment (AI assists but humans decide), or human-only (judgment, relationship, creativity). This does two things: it surfaces the real automation opportunities, and it gives employees ownership over the conversation instead of making them feel like they're being audited for replacement.
The output is a prioritized list of the top 3 to 5 workflows where AI deployment will produce measurable results within 30 days. High-intent targets typically include HR onboarding documentation, technical documentation generation, customer support routing, and financial reporting prep.
1.4 Infrastructure Discovery: Chip-Agnostic Readiness
With the rise of platforms like NemoClaw and OpenClaw, the technical stack is no longer tied to a single cloud provider or hardware vendor.
- Hardware audit: Determining if the company has local compute capacity (Mac Studios, existing NVIDIA clusters, underutilized server hardware) to host high-privacy models. Many mid-market companies have more compute sitting idle than they realize.
- The "Any Chip" strategy: Preparing the organization to run models on existing infrastructure, reducing dependency on expensive, proprietary SaaS APIs where appropriate. This is particularly relevant for companies in regulated industries where data residency matters.
- Data pipeline mapping: Inspecting the plumbing of internal wikis, CRMs, Slack, email archives, and technical repositories to assess RAG-readiness. The typical mid-market company's data infrastructure is fragmented: databases that don't talk to each other, no vector store, inconsistent API access, and tribal knowledge trapped in email threads and one person's head.
Month 1 deliverables: Shadow AI risk report with dollar exposure, interim usage policy, workflow priority matrix, infrastructure readiness assessment, and the business case for Month 2 investment.
II. Month 2: The Foundation and Pilot (Days 31 to 60)
Objective: Establish permanent AI governance, deploy the first production-grade AI system, and build the change management foundation that makes Month 3 possible.
Month 2 is where the real work starts. The audit gave you the map. Now you build.
2.1 The AI Council and Governance Framework
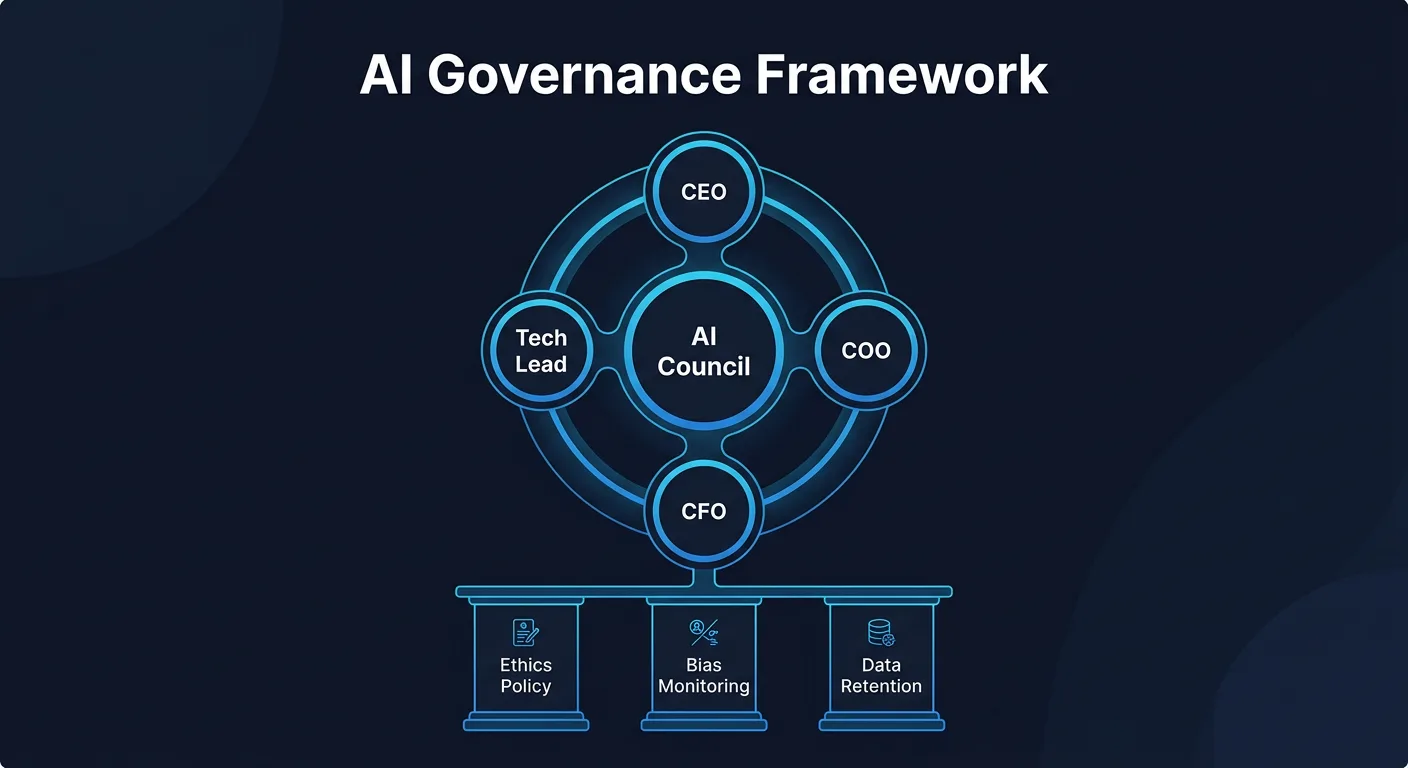
Strategic AI requires more than code. It requires organizational alignment, and that means creating a governance structure that outlasts the fractional engagement.
Council composition: CEO or COO (sponsor), CTO or head of IT (technical owner), 1 to 2 department heads from the highest-priority workflows, a legal or compliance representative, and 1 to 2 "AI champions" from frontline teams. The champions matter more than most people think. They're the ones who translate board-level strategy into daily adoption.
The council meets biweekly during the 90-day engagement, then transitions to monthly. Their charter covers:
- AI project approval and prioritization
- Data governance and privacy policies
- Budget allocation for AI tools and infrastructure
- Ethical guidelines: transparency, bias mitigation, data retention
- Incident response procedures for AI-related failures
Executive readiness training runs parallel. The leadership team needs to understand how to manage an "agentic workforce," treating AI systems as digital employees with specific KPIs, oversight requirements, and failure modes. This is a mindset shift, and it doesn't happen in a single presentation.
2.2 Vendor Evaluation: Cutting Through the Noise
The AI vendor landscape in 2026 is a minefield of overclaiming. Every SaaS tool claims to be "AI-powered." Most of them bolted a chatbot onto an existing product and tripled the price. The fractional CAIO's job is to separate real capability from marketing.
We evaluate vendors across six dimensions:
- Technical fit: Does the tool actually solve the workflow problem identified in Month 1, or does it solve an adjacent problem and require workarounds?
- Data handling: Where does data go? Is it used for model training? What's the retention policy? Can you run it in your own VPC?
- Governance and compliance: Does the vendor meet your regulatory requirements? Can they provide SOC 2 Type II, HIPAA BAA, or GDPR DPA as needed?
- Security and reliability: What's the uptime history? What happens during an outage? Is there a fallback?
- People and adoption: How steep is the learning curve? What training and support does the vendor provide? What does their customer success model look like?
- Value and ROI: What's the actual cost per user/task/month? How does that compare to the current process cost identified in the audit?
The rule: demand proof-of-concepts, not demos. Reject anything that looks like rules-based automation mislabeled as AI. Require architecture diagrams and reference customers you can actually call.
2.3 POC Deployment: The First AI Fleet
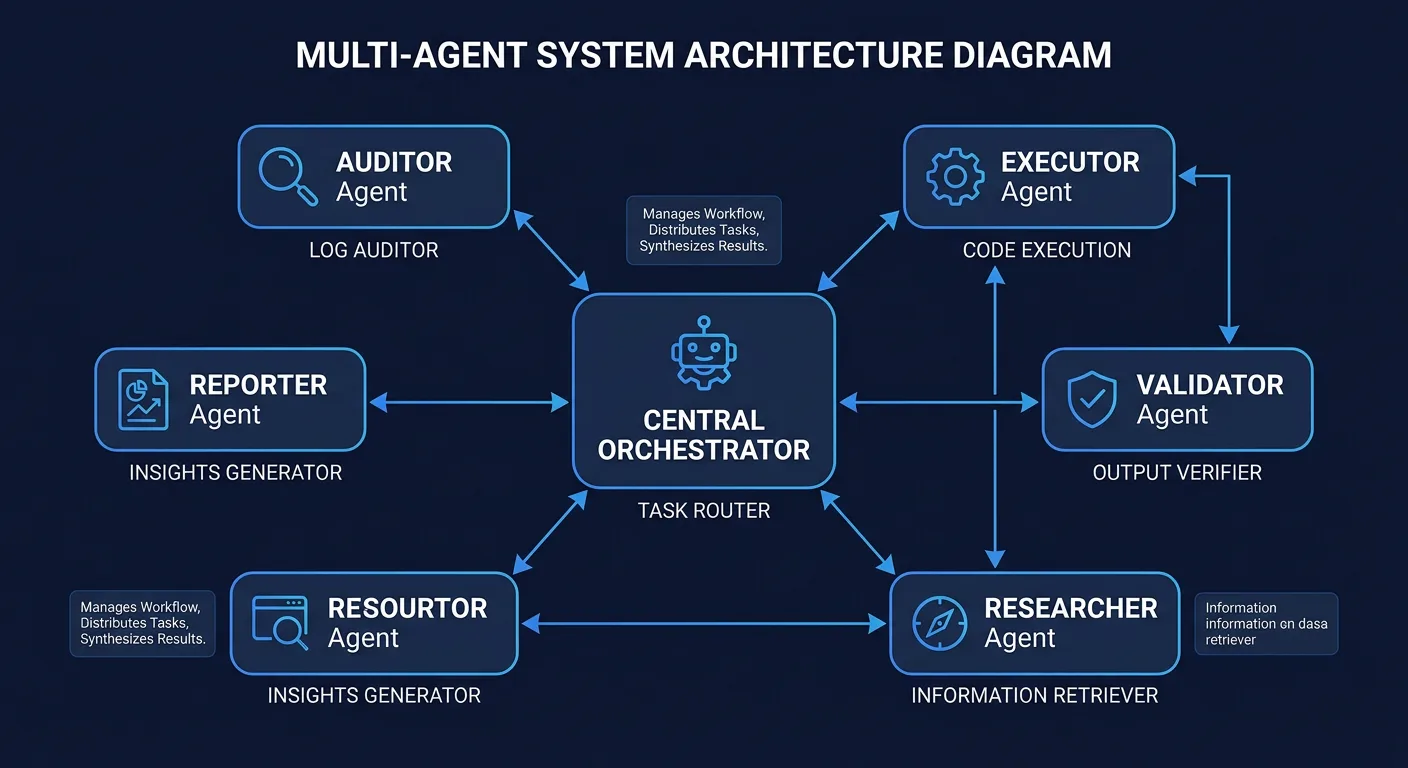
We deploy the first functional AI system using the same methodology that yielded a 9.1 percentage point performance gain in recent enterprise stress tests.
- Agent persona mapping: Designing specific roles for each agent in the fleet. The Auditor reviews inputs. The Executor handles the core task. The Validator checks output quality. This separation of concerns prevents the single-agent failure mode where one system tries to do everything and does nothing well.
- Sandbox provisioning: Creating a secure environment where agents can plan and act without touching core production data. This is non-negotiable for the first deployment. You can relax constraints later once the system proves reliable.
- Multi-step workflow integration: Moving beyond simple chat interfaces to plan-and-act agents that autonomously interface with tools like Jira, GitHub, Salesforce, or whatever the client's operational stack looks like.
POC selection criteria: The first pilot needs to be high impact, low risk, and measurable within 30 days. Ideally it targets a "toil" task that employees actively dislike. That combination gives you the best chance of early adoption and clear metrics. Build in explicit success and fail criteria before starting. If you can't define what success looks like in advance, you're not ready to build.
2.4 RAG Implementation and Data Hardening
Making AI smart about your company's specific knowledge without compromising security.
- Vector database deployment: Setting up local or secure-cloud vector stores (Qdrant or Milvus) to hold the organization's knowledge base. For most mid-market deployments, Qdrant handles 50,000 documents in roughly 8GB of RAM with sub-50ms query latency.
- Hybrid retrieval: The 2025 production standard combines keyword search (BM25, weighted at 0.3) with vector search (weighted at 0.7). This hybrid approach boosts precision by 15% to 30% compared to vector-only retrieval. Target metrics: under 3 seconds end-to-end latency, 90%+ answer rate, $2 to $8 per 1,000 queries.
- Intelligent chunking: How you break documents into retrievable pieces matters enormously. The default 100-word fragment approach that most tutorials teach produces garbage results. We chunk by semantic boundaries: sections, paragraphs, and logical units that preserve context.
- Validation framework: 70% of RAG systems in production lack systematic evaluation. We establish a scoring system where both human experts and "judge agents" validate output against standardized rubrics. Weekly embedding quality reviews catch drift before it reaches users.
2.5 Change Management: The Human Side
This is where most AI initiatives fail, and it has nothing to do with technology. Research from BCG and Columbia Business School found that employee-centric approaches account for one-third of AI adoption success. You can build a technically perfect system that nobody uses because you didn't bring people along.
The change management playbook during Month 2:
- Visible leadership adoption: The CEO, COO, or whoever sponsors this initiative needs to visibly use AI tools in their own work. Not performatively. Actually use them. People watch what leaders do, not what they say.
- Change champions: Identify 1 to 2 people per department who are already AI-curious. Give them early access to the pilot. Let them become the internal experts their peers go to with questions. Peer influence beats top-down mandates every time.
- Co-design workshops: Instead of telling employees what's being automated, involve them in the task categorization exercise from Month 1. When people classify their own work as "automate, augment, or human-only," they feel ownership over the change instead of being subjected to it.
- Protected experimentation time: Give teams explicit permission and dedicated hours to experiment with AI tools. The companies that get the fastest adoption are the ones that remove the risk of "wasting time" on learning.
Month 2 deliverables: AI governance charter, vendor evaluation report, deployed POC with baseline metrics, RAG knowledge base (v1), change management plan with identified champions, and initial training materials.
III. Month 3: Execution, Scale, and Handover (Days 61 to 90)
Objective: Migrate the pilot to production, establish the security and monitoring framework, train the internal team, and hand over a self-sustaining AI operation.
3.1 Production Migration: The Three-Gate Deployment
Moving from "pilot that works in a sandbox" to "production system the business depends on" follows a three-gate process:
- Gate 1, Shadow Mode: The AI system runs in parallel with the existing human process. Both produce output. Results are compared. This catches edge cases and builds confidence without risk. Typical duration: 5 to 7 days.
- Gate 2, Human-in-the-Loop (HITL): The AI system handles the primary workflow, but every output gets human review before it reaches a customer or downstream system. This is where you tune thresholds and identify the "last 10%" of edge cases that always take longer than expected. Typical duration: 7 to 14 days.
- Gate 3, Autonomous with Monitoring: The system operates independently with automated quality checks and alerting. Humans review exceptions and periodic samples. Rollback procedures are documented and tested.
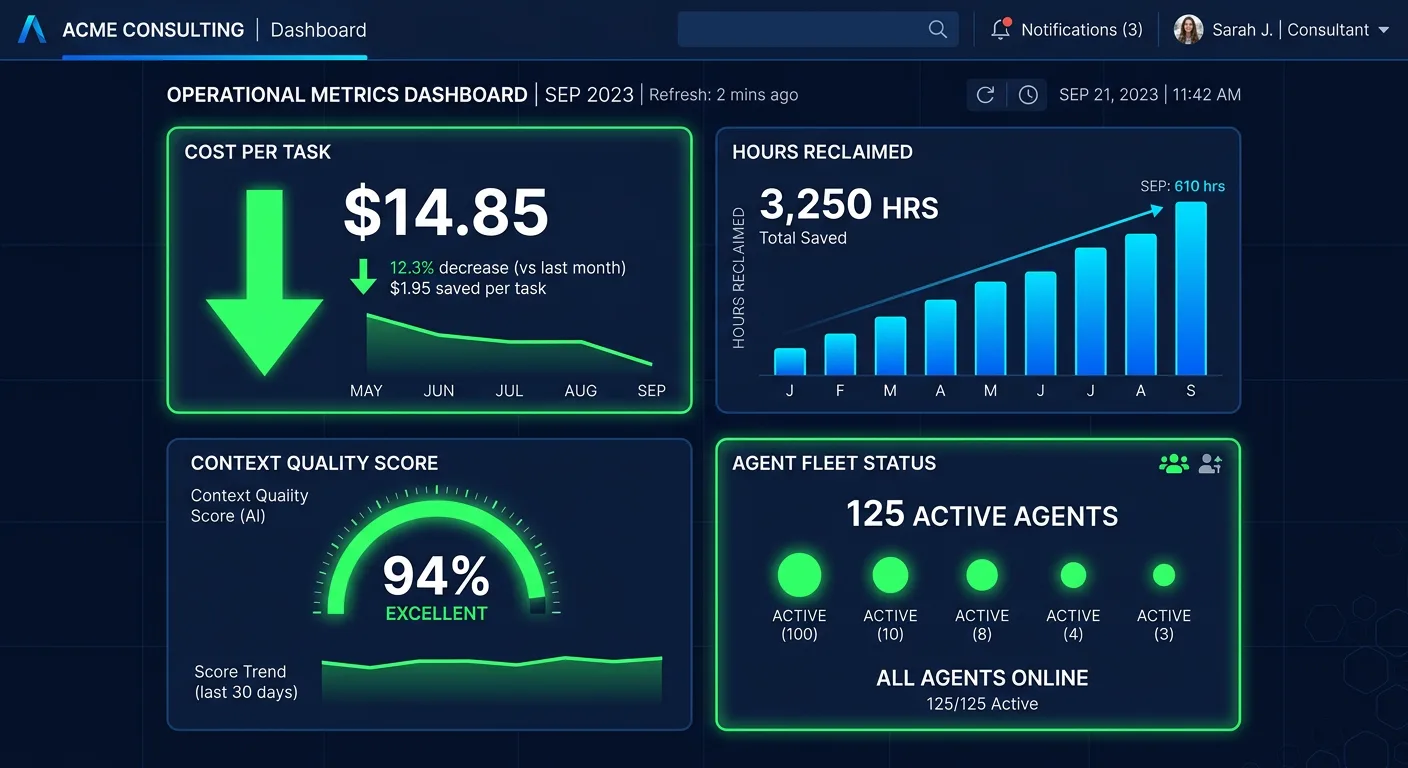
The ROI dashboard goes live at Gate 1 and tracks three metrics in real time:
- Cost-per-task: Direct comparison against previous human labor costs for the same work.
- Time reclaimed: Cumulative hours saved per department, translated to dollar value.
- Quality scores: Monitoring for hallucination rates, factual accuracy, and output consistency. Any degradation triggers a Gate rollback.
3.2 Security Framework for Production AI
Security in production AI is a different animal than traditional application security. The OWASP Top 10 for Agentic Applications, published in December 2025, outlines the specific threat landscape:
- Agent Goal Hijacking: Adversarial inputs that redirect an agent away from its intended task. Mitigated by input validation, system prompt hardening, and output monitoring.
- Tool Misuse: Agents using connected tools in unintended ways. Mitigated by command whitelisting, least-privilege access (RBAC/ABAC), and sandbox execution in containers.
- Memory Poisoning: Corrupted context or conversation history leading to degraded outputs over time. Mitigated by context window management, periodic memory resets, and validation of retrieved context.
Every production deployment gets a zero-trust architecture: micro-segmented access, PII filtering before data reaches any cloud model (using tools like AWS Bedrock Guardrails or Lakera Guard), and comprehensive audit logging. 80% of organizations face AI-related security incidents, but only 42% invest adequately in AI security. We don't let our clients become part of that statistic.
3.3 The Scale-Up Roadmap and Cost Optimization
Once the first system is proven, we map the expansion using Month 1's priority matrix.
- Next four use cases: The audit identified the top workflows. The first one is live. The next four get sequenced based on what we learned from the pilot: which integration patterns work, what training the team needs, and where the data infrastructure has gaps.
- Tiered model strategy: Routine tasks move from frontier models (Claude Opus, GPT-5) to worker models (Gemini Flash, Llama 3 local) to drive down inference costs by 60% or more. The typical mid-market deployment runs $350 to $800 per month across all tiers combined, a fraction of single-vendor enterprise SaaS contracts.
- Local compute ROI: For companies processing high volumes of sensitive data, we model the break-even point for purchasing dedicated hardware versus continuing with cloud-based inference. The answer depends on volume, data sensitivity, and whether the company already has underutilized compute resources from the infrastructure audit.
3.4 Team Training and Upskilling
Generic "AI 101" training is a waste of everyone's time. We build function-specific training programs that teach people to use AI in the context of their actual work.
- Prompting skills: Not just "write better prompts." Teaching the mental model of delegating to AI: how to break tasks into specifications, how to evaluate output critically, and how to iterate when the first result isn't right.
- Department-specific playbooks: Marketing gets trained on AI-assisted content and campaign workflows. Finance gets trained on AI-assisted reporting and analysis. Engineering gets trained on AI-assisted code generation and review. Same tool, different applications, different training.
- Judgment with human-in-the-loop: The critical skill isn't knowing how to use AI. It's knowing when AI is wrong. We train teams to develop calibrated trust: understanding the specific failure modes of the tools they're using and building habits around verification.
- Certification and incentives: Internal badge or certification systems tied to demonstrated competency. Some clients offer stipends or bonuses for completing training milestones. The investment signals that this is a priority, not a side project.
3.5 The Handover
The fractional CAIO's goal is to make the organization self-sufficient. Not dependent. Not locked into a consulting engagement that never ends. The 90-day handover package includes:
- Infrastructure documentation: Version-controlled configuration files, deployment runbooks, escalation procedures, and monitoring dashboard access. Everything required to operate, maintain, and troubleshoot the deployed systems.
- Vendor and model records: Current vendors, contract terms, model versions, API keys, and the rationale behind each technical decision. When someone asks "why did we choose Qdrant over Pinecone?" in six months, the answer is documented.
- The 3-Year AI Maturity Index: A strategic roadmap presented to the board covering the progression from current state to a fully "AI-first" operation. This includes staffing recommendations, budget projections, and technology milestones.
- Talent gap report: Where the company needs to hire full-time AI engineers, data scientists, or ML ops specialists. What those roles look like, what they cost, and when in the maturity timeline they become necessary.
- Final ROI substantiation: Hard data proving efficiency gains and annualized savings from the pilot deployment. For most mid-market engagements, the target is $100K or more in annualized savings from the initial pilot workflows alone, against a fractional CAIO engagement cost that's a fraction of that.
3.6 Beyond Day 90: The Ongoing Advisory Model
The intensive 90-day engagement transitions to a lighter advisory relationship. What that looks like in practice:
- Monthly check-in calls to review AI performance dashboards and address emerging issues
- Quarterly strategic reviews aligned with the 3-year maturity roadmap
- On-call availability for incident response or major vendor decisions
- Annual AI strategy refresh to incorporate new model capabilities and shifting business priorities
The cadence adjusts based on where the company is in its maturity curve. Some clients need heavier support for 6 months post-engagement while they hire their first full-time AI role. Others are self-sufficient within weeks of handover. Both are good outcomes.
Common Pitfalls That Derail AI Initiatives
After running this playbook multiple times, the failure patterns are predictable. Here are the ones that show up most often:
1. Starting with technology instead of problems. Companies that pick an AI tool first and then look for problems to solve with it almost always waste money. McKinsey's data shows 42% of AI projects get abandoned due to unclear value. The audit-first approach exists specifically to prevent this.
2. Underinvesting in change management. Building a technically excellent system that employees refuse to use is the most expensive form of waste. The BCG-Columbia research is clear: one-third of adoption success comes from how you handle the human side. Budget for it.
3. Skipping the measurement baseline. Only 51% of companies track AI ROI confidently. If you don't measure the "before" state rigorously, you can't prove the "after" state improved. Baseline measurement happens in Month 1, not Month 3.
4. Treating all AI use cases equally. The workflow that saves your customer support team 3 hours per day is not the same priority as the one that generates slightly nicer internal reports. Ruthless prioritization based on the ROI matrix is the difference between a successful pilot and a science project.
5. No plan for what happens after the engagement ends. The best AI deployment in the world degrades without maintenance, monitoring, and ongoing optimization. The handover package and advisory model exist because AI systems are living systems, not one-time installations.
The Bottom Line
The average ROI for AI implementation sits at $3.70 per dollar invested, with leaders seeing up to $10.30. Targeted pilots hit breakeven in 1 to 3 months. 74% of companies see positive ROI within the first year.
But those numbers only happen with structured execution. The 90-day roadmap works because it's sequenced correctly: understand the problem before building the solution, prove value before scaling, and build organizational capability before handing over the keys.
If you're a mid-market company sitting on the AI sideline, the cost of waiting is compounding. Your competitors are already running through some version of this playbook. The question isn't whether to start. It's how fast you can move from audit to production.
A fractional Chief AI Officer gets you there in 90 days, at a fraction of the cost of figuring it out through trial and error. The math works. The methodology is proven. The only variable is when you decide to start.
Frequently Asked Questions
A Fractional Chief AI Officer (CAIO) is a part-time executive responsible for an organization's AI strategy, governance, and technical implementation. This model allows mid-market companies to access high-level expertise without the $300k+ salary of a full-time hire.
The most common failure modes include: Described but not Delivered (strategy without technical plumbing), Context Leakage (agents failing to maintain data privacy within prompts), and Infinite Loops (poor orchestration leading to excessive token spend without task completion).
ROI is calculated by measuring the Reduction in Cost-per-Task and Total Hours Reclaimed. For example, automating an HR onboarding workflow using a multi-agent fleet typically results in a 42% reduction in labor hours within the first 60 days.
Yes. Modern platforms like NemoClaw and OpenClaw allow for chip-agnostic deployment, meaning organizations can run powerful models on existing hardware or secure VPCs rather than relying on public SaaS APIs.
A Privacy Proxy architecture is implemented where all sensitive data is scrubbed of PII (names, SSNs, credit cards) before being processed by a cloud LLM, or the entire stack is hosted locally/in-VPC to prevent data from ever leaving the company's control.